Using List.Contains To Filter Dimension Tables
/In order to make a clean user experience for Power BI report consumers, I will limit the data in my Dimension tables to only include data that is in the Fact tables. For example, a customer dimension table might have 1,000 customers in it, but the sales fact table may only have 400 customers in it. This can happen because the sales data is limited to recent years, or specific regions, for a given report.
I don’t like loading up a slicer with dozens or hundreds of items that have no corresponding records. The same would apply if there was no slicer, but the consumer wanted to filter using the Filter pane. So I’ll filter the customer table so it only includes what I would call “active customers” that are shown in the sales table.
The most straight forward way to do this is by doing an Inner Join between the tables, but there is another way, using the powerful List.Contains() feature of Power Query. And what makes it so powerful is not just it’s utility, but when you run it against data in a SQL Server or similar server, Power Query will fold the statement.
Let me walk you through both methods so it is clear. I’ll be using the WideWorldImportersDW database. If you are a Power BI developer and don’t have a local copy of SQL Server and some test databases on your machine, you are doing yourself a disservice. See this video for quick instructions on getting SQL Server and some test databases up and running. All of the products are free.
There is a Power BI file attached below but you can easily follow along in a new PBIX file for these examples. For both example, you’ll need to connect to the Fact Sales and Dimension Stock Item tables. There are 627 items in the Stock Item table, but only 227 unique items in the Fact Sales table. So any slicers or filters would have 400 unnecessary items. Those are what we want to get rid of. First, let’s do the Inner Join method.
Inner Join to Limit Records in the Dimension Stock Item Table
First, we need a unique list of items from the Fact Sales table to work with. To do this, right-click on the Fact Sales table, and create a reference. Right-click on that newly created query and make sure it “Enable Load” is not checked. This table will not be loaded to the data model.
Right-click on the Stock Item Key field in this query and select Remove Other Columns. This step isn’t necessary, but it makes the query logic a bit easier to understand.
Right-click on the Stock Item Key and select Remove Duplicates. Power Query will probably tell you in the lower left you have 227 rows.
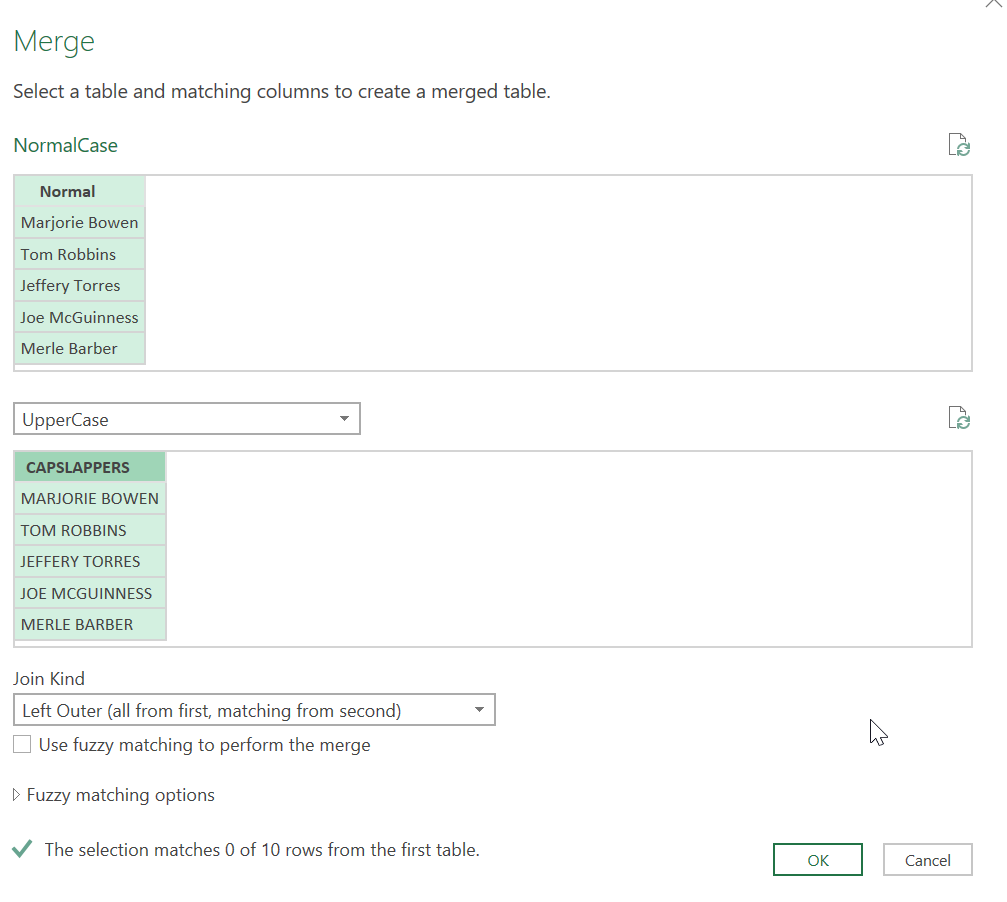
From the Dimension Stock Item Table, click on the Merge Queries button on the Home Ribbon.
Select the Stock Item Key column in the window.
Select the Fact Sale (2) table in the dropdown. This is the one we created a few steps ago. Then select the Stock Item Key field.
Select “inner” for the Join Kind. Your screen should look like this. You’ll notice it found 227 matches out of the total 627 items in the Dimension Stock Item table

Press Ok, then expand the field.
Right-click on the newly expanded Stock Item key.1 field and remove it. If you were to delete this field before you expanded it, it would have broken query folding, which means all data would have to be brought back to your Power Query engine and processed locally, or in the on-prem gateway if this were refreshing in the service. But by expanding and then deleting the field, it has the SQL Server do all of the work for you.
Now your Dimension Item Table has 227 records, which is the same number of unique items sold in the Fact Sales table. And it all folds.
There is another way to do this though, and it has some advantages.
List.Contains() to Limit Records in the Dimension Stock Item Table
The first few steps are the same:
Right-click on the Fact Sales table, and create a reference. Make sure it is not set to load to the data model. I’m going to rename this query ActiveItemList to make things easier, because we’ll be manually typing it in later.
Remove all but the Stock Item Key fields.
Remove duplicates. You should have 227 records.
Now we need to convert this to a list. This is actually simple. Right-click on the Stock Item Key field, and select Drill Down. This is necessary because List.Contains operates on lists as its name implies, not tables, fields, etc.

Now you have the 227 items in a list, not a table. The Drill Down command just added the field name in brackets to the table name, so you will see something like this in the formula bar:
Now we are ready to filter our Dimension Stock Item table. Go back to that table. You should delete the Inner Join merge and expansion steps from the previous example.
Filter the Stock Item Key by unchecking any item. Doesn’t matter which one. We just want Power Query to get the formula started for us. You will have something like this in the formula bar:
We are going to remove the ([Stock Item Key] <> 2) part, and make the entire formula look like this:
List.Contains() takes our list named ActiveitemList and compares it to each value, the [Stock Item Key] field, in the Dimension Stock Item table and only keeps those that return true, i.e., a match was found.
You may think that this method is not too efficient. And you would be right, except for what Power Query does with this statement when folding is going on with a SQL Server. If you used this logic on a few hundred thousand rows from a CSV file, SharePoint list, or other source that didn’t fold, this would take forever. The Inner Join method is much faster for those scenarios, but the Inner Join method has more steps, it takes a bit more effort to set up, and the logic of why you are merging a table then deleting what you merged isn’t immediately clear when your future self is reviewing and modifying the code.
Power Query takes the List.Contains() logic and turns it into a SQL IN operator and lets the server do the work. If you right-click on this step in the Query Properties list, and select View Native Query, you’ll see something like this, which is the SQL statement sent to the server.

So which is better? It depends. If you have relatively small data set, say data from Excel, a CSV file, or a smaller SharePoint List, then List.Contains() will do fine. Anything under 10K records or perhaps a bit more would be ok. A dataset of any size will work fine with a source that will fold your statement, like SQL Server.
There are two reasons I like List.Contains() though and prefer it over an Inner Join when the data set allows it:
The logic is cleaner. I am just filtering a column by a list. Not merging another table then deleting the merge. It is just one step in the Query Properties, a Filtered Rows operation. It is immediately clear what this step is doing.
I can easily create a manual list to filter off of if I just want a few items. For example, if I only wanted a few products in the example above, my ActiveItemList could be one of the manual lists like below rather than a list generated from another table. The first example is few manually chosen numbers, the latter all items from 200 through 250. Creating a normal filter
= {200, 201, 202, 210, 254}
= {200..250}
So there you have it. Another way to filter one table from another set of data. See my Power BI file here.
Edit Oct 27, 2020 - to make this run much faster, do the following:
In your list, right-click on the last step of the list and select “Insert Step After”
Whatever is in the formula bar, wrap it with List.Buffer().
This will cause the list to be processed by Power Query much faster and create the native query almost instantly. The server will run the query at the same speed, which will be very fast. This will radically cut down on the time it takes Power Query to generate the SQL statement though, especially on larger lists.
Thanks to Nathan Watkins on Twitter for this suggestion.